In most areas of science, we need to do data analysis, and evolutionary psychology was no exception to that. A decade ago!, I was taught to use SPSS for data analysis. Recently, I see that R has been the rising star among psychologists. In this blog, I will try to show how to explore your data in Python. Because, why not Python?
Prepare a .csv document and save it in the same directory with your .py file
For the sake of this example, I prepared a .csv document, “mydata”. Then, I installed “pandas” module. Now, time to read our .csv document:
import pandas as pd
df = pd.read_csv("/Users/Documents/datapreparation/mydata.csv")
print(df)
The output should look like this:
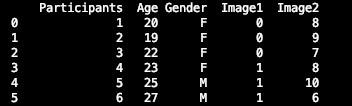
As you see, I created 5 columns (Participants, Age, Gender, Image1, and Image2). Let us assume that our participants rated two images in terms of attractiveness, and that this is our data frame (Image1 did not look attractive, huh?). At the very left, you will see numbers without a header. This is the index of Python and it starts counting from 0.
If you want to see the first three rows of each column:
import pandas as pd
df = pd.read_csv("/Users/datapreparation/mydata.csv")
print(df.head(3))The output should look like below:
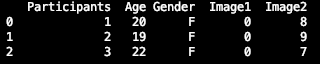
If you want to see the last three rows of each column, you only need to replace the last line of the previous code with:
print(df.tail(3))
If you want to see only the headers:
print(df.columns)
If you want to see only one specific column, for example “Age”:
print(df["Age"]) #another way of doing this: print(df.Age)
Or perhaps, you only want to see the first five rows of the “Age”:
print(df["Age"][0:5])
Pay attention to the detail that Python does not include the last item, and that it starts counting from 0. Now, let us assume that you want to see the second, the third, and the fourth row (of each column):
print(df.iloc[1:4])
If you want to read a specific data, for example the third row of the second column:
print(df.iloc[2, 1])
You may also wonder about the 19-year-old participants’ data:
print(df.loc[df["Age"] == 19])
The output will be as below:

If you want to sort your data according to the variable “Age”:
print(df.sort_values("Age"))If you want to sort the data in a descending fashion:
print(df.sort_values("Age", ascending=False))Cheers!